
ITパスポート試験(シラバス6.4) テクノロジ系 基礎理論 の出題傾向、学習ポイント、重要な用語を説明します。
「基礎理論」出題傾向
4 問程度/テクノロジ系45問
*令和元年~令和7年過去問題(公開)による
一定の割合で、シラバスの新出用語とシラバスにない用語が出題される傾向があります。
シラバスに掲載されて間もない用語(Ver.4.0以降の新出用語)に、初めて掲載されたときのシラバスのバージョン(Ver.4.0等)を表示しました。
離散数学
2進数
2進数は、0、1の2種類の数字を用いて表す数値です。
| 10進数 | 2進数 |
|---|---|
| 0 | 0 |
| 1 | 1 |
| 2 | 10 |
| 3 | 11 |
| 4 | 100 |
| 5 | 101 |
| 6 | 110 |
| 7 | 111 |
| 8 | 1000 |
問題をチェック! R3年 問66(計算問題)
基数変換の方法
10進数から2進数への変換について、次のような問題が出ています。
問題をチェック! R2年 問62(計算問題)
表現可能な数値の範囲
次のような問題が出ています。
考え方に慣れておきましょう。
問題をチェック!
R3年 問66(計算問題)
R元年 問80(計算問題)
R元年 問82(計算問題)
応用数学
組合せ
組合せは、人や物を選び出す問題です。
次のような問題が出ています。
問題をチェック! R元年 問72(計算問題)
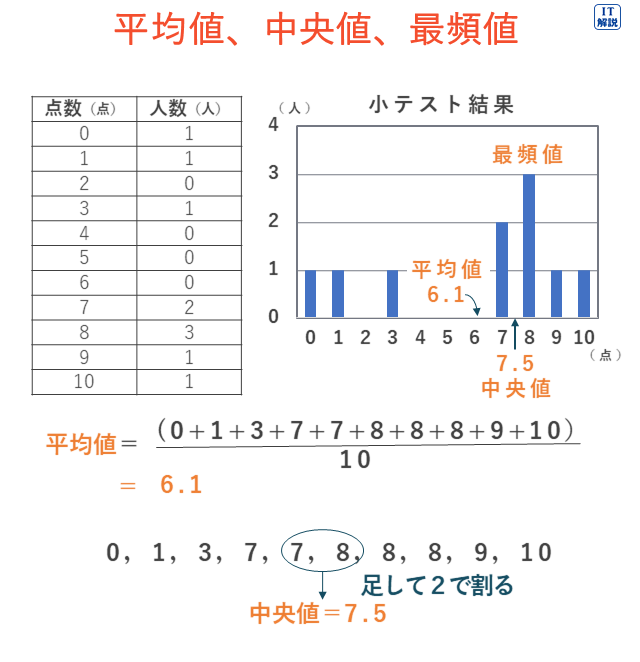
平均値
平均値は、すべてのデータの値を足して、それをデータの個数で割った値です。
平均値、中央値、最頻値の違いについてのグラフをご覧ください。
問題をチェック! R4年 問59(計算問題)
中央値(メジアン)
Ver.5.0
中央値は、データを値の小さいほうから順にならべたときに、ちょうど半分にデータを分ける値です。
平均値、中央値、最頻値の違いについてのグラフをご覧ください。
問題をチェック! R4年 問59(計算問題)
最頻値(モード)
Ver.5.0
最頻値は、その値が起こる頻度が最も高い値です。
平均値、中央値、最頻値の違いについてのグラフをご覧ください。
標準偏差
Ver.5.0
標準偏差は、データの散らばりの大きさを表す指標で、大きいほど、データが散らばっていることを示します。
記号σ(シグマ)で表します。
分散の平方根に等しいです。
偏差値
偏差値は、得点が全体の中のどのくらいの位置にあるかを示すものです。
偏差値は、次の式で求められます。
偏差値=(得点−平均点)÷標準偏差×10+50
問題をチェック! R5年 問77(計算問題)
分散
Ver.5.0
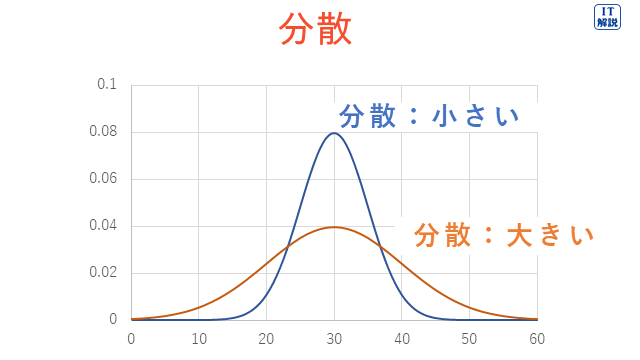
分散は、データの散らばりの大きさを表す指標で、大きいほどデータが散らばっていることを示します。
記号Vで表します。
標準偏差の2乗に等しいです。
問題をチェック! 基礎 予想2
正規分布
シラ外
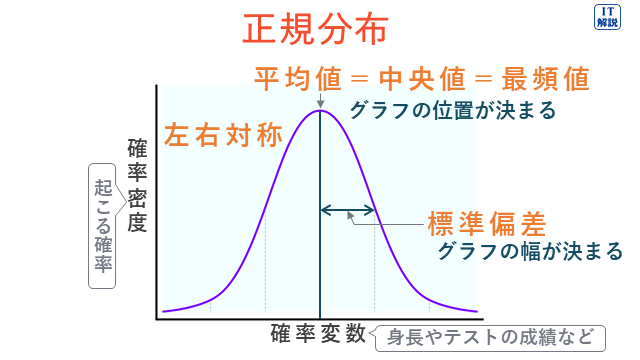
正規分布は、どの値をとるか確実には分からない変数について、値ごとに生じる確率を表したものです。
図のような釣り鐘のような形をしていて、平均値の生じる確率が最も大きく、平均値から離れるほど、生じる確率は小さくなっています。
自然界や人間の行動・性質など様々な現象に対して、よく当てはまります。
問題をチェック! 基礎 予想1
相関係数
Ver.5.0
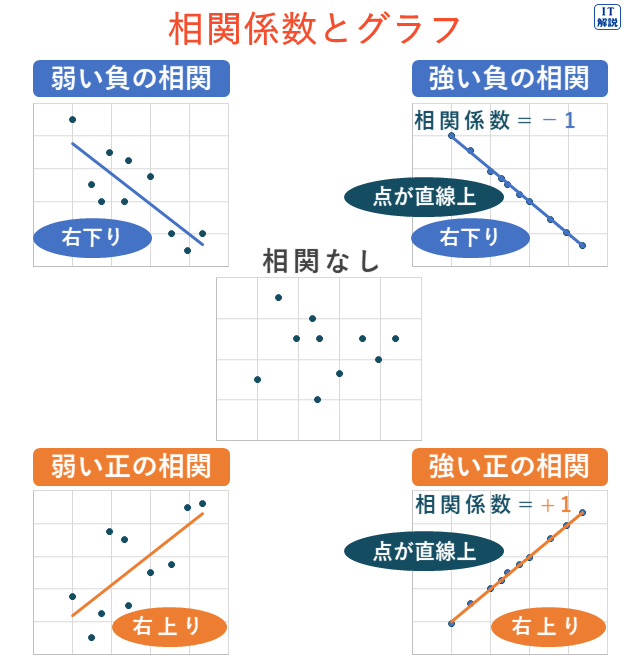
相関係数は、相関の強さを表す指標で、-1から1の間の値をとります。
2つの変量が正の相関関係にある場合、正の値をとり、負の相関関係にある場合、負の値をとります。
いずれの場合も相関が強いほど1に近い大きな絶対値をとります。
推定
Ver.5.0
推定は、一部のデータの特徴から全体の特徴を予想することです。
仮説検定
Ver.6.0
仮説検定は、母集団に関するある仮説が統計学的に成り立つか否かを、標本のデータを用いて判断することです。
導き出したい結論が正しいと判断するときに、導き出したい結論とは逆の仮説(帰無仮説)を仮定して、この仮説が正しいとは言えないことを証明することで、導き出したい結論が正しいとします。
(総務省統計局解説より)
回帰分析
Ver.5.0
回帰分析は、結果となる数値と要因となる数値の関係を、式で表してを明らかにする統計的手法です。
回帰分析の結果に基づいて、将来の数値を予測することができます。
また、この時、作成される線を回帰線あるいは回帰直線といいます。
説明変数
Ver.5.0
説明変数は、要因となる数値です。
目的変数
Ver.5.0
目的変数は、結果となる数値です。被説明変数とも言います。
相関分析
Ver.5.0
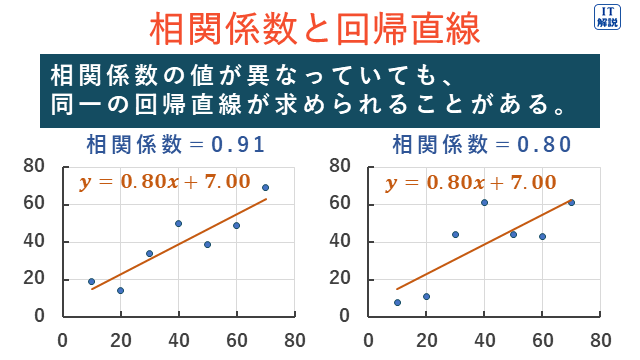
相関分析は、一方の変量が変化すると、他方もそれに応じて変化する関係を明らかにする統計的手法です。
分析者による因果関係の仮定は、ありません。
分析目的は、変数間の(直線的な)関係の強さを測定することです。
取り扱う変数の種類数は、2種類(1対1)です。
数値計算
Ver.5.0
数値計算は、解を数値で得ることです。
数値解析
Ver.5.0
数値解析は、様々な現象を数学的なモデルで表現し、コンピュータを使って再現・予測することです。
数式処理
Ver.5.0
数式処理は、コンピュータで数式(記号)を用いて計算します。
データの集計(和、平均)
Ver.5.0
データの比較のために、データの集計(和、平均)を求めます。
データの並べ替え
Ver.5.0
データの比較のために、データの並べ替えをします。
ランキング
Ver.5.0
データの比較のために、ランキングを求めます。
線形代数
Ver.5.0
線形代数は、多くの変数に関するデータを取り扱うのに便利な数学です。
ベクトル
Ver.5.0
ベクトルは、線形代数のツールです。
行列
Ver.5.0
行列は、線形代数のツールです。
1変数関数の微分と積分
Ver.5.0
微分は、データの変化の度合いを知るのに便利なツールです。
積分は、変化の蓄積した結果を知るのに便利なツールです。
名義尺度
Ver.6.0
名義尺度は、順序や大小がないデータです。
例えば、国籍、男女、血液型などです。
問題をチェック! R7年 問63
順序尺度
Ver.6.0
順序尺度は、何らかの順序が明確なデータです。
例えば、テストの順位、検定試験の級などです。
問題をチェック! R7年 問63
間隔尺度
Ver.6.0
間隔尺度は、その数値やその間隔には共通認識がありますが、ある値を別の値で割っても意味をなさないデータです。
例えば、時刻、気温などです。
問題をチェック! R7年 問63
比例尺度
Ver.6.0
比例尺度は、ある値と別の値の程度を比によって表すことができるデータです。
例えば、経過時間、速度、年齢、体重などです。
問題をチェック! R7年 問63
誤差
Ver.5.0
コンピュータ内部では、あらかじめ定められた範囲でしか数値を表現できません。
範囲を超える場合には、実際に近い値(近似値)を使います。
そのため、コンピュータで計算した値は、実際の値と異なる場合があり、実際の値と誤差が生じてしまいます。
問題をチェック! 基礎 予想5
グラフ理論
Ver.6.0
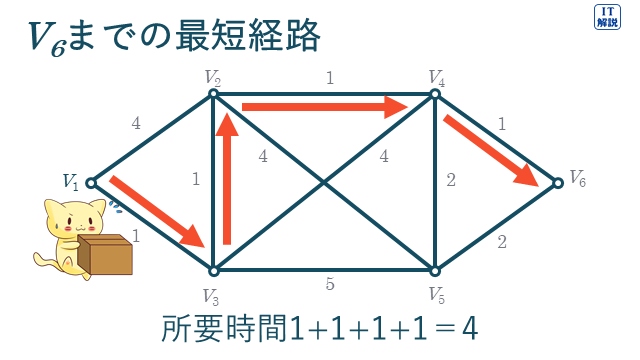
グラフ理論は、インターネットでの検索や最短所要時間の経路の検索など、ネットワークに関する基礎理論の1つです。
モノとモノのつながりを、グラフ(点および辺からなる抽象的な幾何学図形)に記述し、解析します。
頂点(ノード)
Ver.6.0
ドットや丸で表します。
辺(エッジ)
Ver.6.0
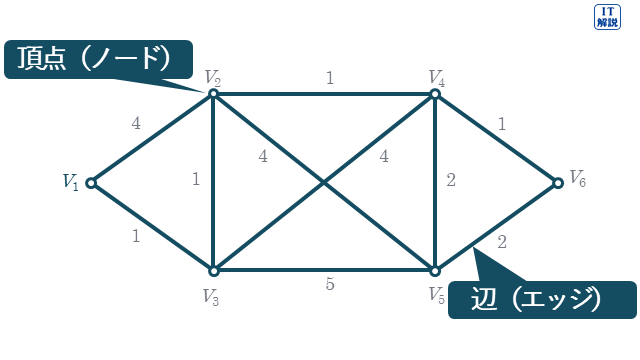
ノード間の接続が、エッジです。
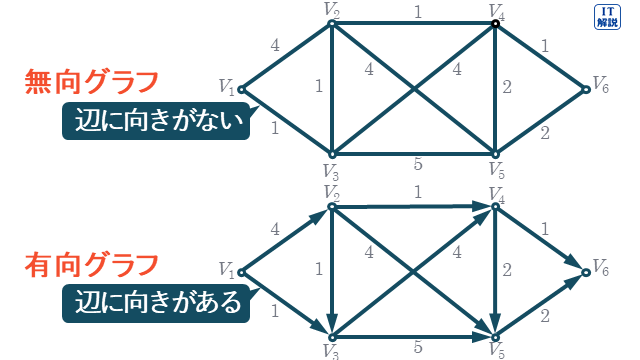
有向グラフ
Ver.6.0
有向グラフは、辺に向きがあるグラフです。
無向グラフ
Ver.6.0
無向グラフは、辺に向きがないグラフです。
最適化問題
Ver.5.0
最適化問題は、与えられた制約条件のもとで、ある目的関数を、最大または最小にする解を求める問題です。
例えば、在庫管理で利用されます。
作業効率や在庫効率を改善し、費用を削減する場面などです。
情報に関する理論
用語の意味をだいたい理解したら,問題演習中心に勉強するといいよ。
参考問題のリンクを利用してね。
国際単位系(SI)接頭語
Ver.6.0
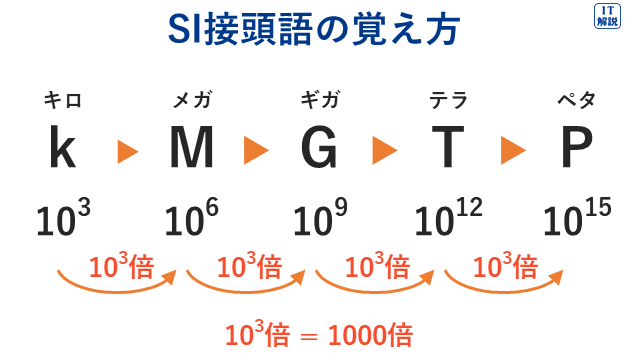
国際単位系(SI)接頭語は、大きな数字や小さな数字を表すのに便利なように、単位の前につける文字です。
例えば、1000g(グラム)=1kg(キログラム)
普段、何気なく使っている「k(キロ)」が接頭語の一つです。
問題をチェック! R5年 問96
アナログデータ
アナログデータは、情報を連続する可変な物理量(長さ、角度、電圧など)で表したものです。
(ITパスポート 令和3年 問89より)
問題をチェック! R3年 問89
デジタルデータ
デジタルデータは、情報を整数のような離散的な数値で表したものです。
(ITパスポート 令和3年 問89より)
離散的な数値とは、整数や自然数のような飛び飛びの値のことです。
次のようなデジタル化の利点が試験に出題されています。
アナログ電圧をディジタル化した後に演算処理すると、演算結果が部品精度、温度変化及び外来雑音の影響を受けにくい。
(基本情報 平成27年秋午前 問4より)
問題をチェック! R3年 問89
文字コード
Ver.6.3
文字コードとは、コンピューターで処理したり通信したりする個々の文字に、固有の番号を割り当てたものです。
例えば、「あ」は1番、「い」は2番、……のような感じです。
問題をチェック! 基礎 予想14
JISコード
Ver.6.3
| JIS コード(ジスコード) | ||
| Japanese(日本) Industrial(産業の) Standards(規格) |
JISコードは、JIS(日本産業規格)で定めた日本語用の文字コードの一つです。
アルファベットや数字、記号などは7ビットまたは8ビットで表します。漢字は16ビットで表します。
文字を表示するのに、文字コードの切り替えの印(エスケープシーケンス)が必要です。
シフトJIS コード
Ver.6.3
シフトJIS コードは、JISコードから派生したコード体系であり、16ビットで表現する文字コードです。
(基本情報 平成19年春 問69より)
問題をチェック! 基礎 予想15
Unicode
Ver.6.3
Unicodeは、多くの国の文字体系に対応できる文字コード体系です。
(基本情報 平成19年春 問69より)
問題をチェック! 基礎 予想16
ワイルドカード
シラ外
ワイルドカードとは、任意の文字を示すための記号のことです。あいまいな文字列などの検索に使われます。
“?“:任意の1文字を表します。
“*”:長さゼ口以上の任意の文字列を表します。
問題をチェック! R元年 問99
述語論理
Ver.5.0
述語論理は、人間の知識や問題をコンピュータで計算できるように表現する手段です。
述語論理は、人間が普段使っている自然な言語を、AIが処理・分析する技術(自然言語処理)に利用されています。
演繹(えんえき)推論
Ver.5.0
演繹(えんえき)推論は、誰もが知っている普遍的な事実を前提として、結論を導き出します。
問題をチェック! R4年 問57
帰納推論
Ver.5.0
帰納推論は、いろいろな事実や事例から導き出される傾向をまとめあげて、結論につなげます。
問題をチェック! R4年 問57
AI
Ver.5.0
| AI(Artificial Intelligence) | ||
| Artificial(人工の) Intelligence(知能) |
現在、確立した定義はありません。
一般に、人間の思考プロセスと同じような形で動作するプログラム、あるいは人間が知的と感じる情報処理・技術といった広い概念で理解されています。
AI、機械学習、ディープラーニングには、下図の関係があります。
| AI | ●一般に、人間の思考プロセスと同じような形で動作するプログラム | |||||
| ●人間が知的と感じる情報処理・技術全般 | ||||||
| 機械学習 | ●AIのうち、人間の「学習に」相当する仕組みをコンピュータ等で実現するもの | |||||
| ●入力されたデータからパターン/ルールを発見し、新たなデータに当てはめることで、その新たなデータに関する識別や予測等が可能 | ||||||
| ディープラーニング | ●機械学習のうち、多数の層からなるニューラルネットワークを用いるもの | |||||
| ●パターン/ルールを発見する上で何に着目するか(「特徴量」)を自ら抽出可能 | ||||||
自然言語処理(NLP)
Ver.6.2
| NLP(Natural Language Processing) | ||
| Natural(自然の) Language(言語) Processing(処理) |
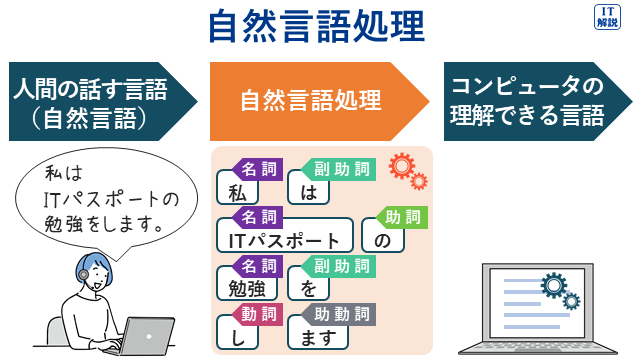
「自然言語」とは、普段私たちが使っている言語のことで、「自然発生的に生まれた言語」のことを指します。プログラミング言語のような「人工言語」と対比する言葉です。
自然言語処理とは、人間の言葉をコンピュータの理解しやすい形に変換し、人間に近い解釈ができるように処理する技術です。
問題をチェック! R2年 問22
音声認識
Ver.6.2
音声認識とは、人の音声から、意味や、音色に関する情報(発声者、性別、喜怒の感情など)を識別する技術です。
音声からテキストを書き起こす議事録の自動化、スマート家電などに利用されています。
画像認識
Ver.6.2
画像認識とは、画像に写っているものの色や形といった特徴を読み取り、それが何であるかを識別して判断する技術です。
画像認識は、顔を特定するスマートフォンの顔認証システム、道路上の物体を検知する自動車の自動運転システム、製造ラインで不良品を発見する異常検知システムなどに利用されています。
基盤モデル
Ver.6.2
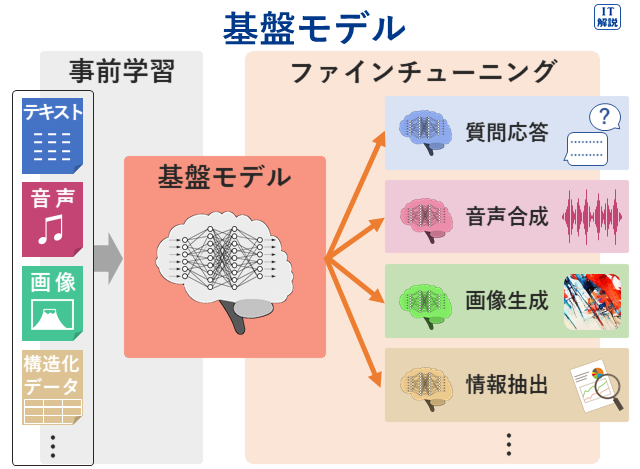
基盤モデルとは、大量で多様な「ラベルなしデータ」を使ってトレーニングを行い、その後、わずかな再トレーニングによって、用途に応じたカスタマイズができる汎用的なAIモデルです。
問題をチェック! R7年 問80
ルールベース
Ver.5.0
ルールベースは、機械学習と並ぶ、AI技術の一つです。
人間がルールを用意しておくことで、問題解決や推論といった知的な処理を、コンピュータに行わせようというものです。
特徴量
Ver.5.0
特徴量は、機械学習においてデータを学習させるために、与えられたデータの特徴を数値化したものです。
機械学習
Ver.5.0
機械学習は、AIに関わる分析技術の一つです。
コンピュータに大量のデータを学習させ、データから規則性や判断基準を発見し、それに基づき未知のものを予測、判断する技術です。
問題をチェック!
R7年 問85(計算) R5年 問76(計算)
教師あり学習
Ver.5.0
教師あり学習は、正解データを与えて学習させます。
次のような教師あり学習の例が試験に出題されています。
正解のデータを提示したり、データが誤りであることを指摘したりすることによって、未知のデータに対して正誤を得ることを助ける。
(基本情報 平成31年春午前 問4より)
問題をチェック! 基礎 予想6
教師なし学習
Ver.5.0
教師なし学習は、正解データを与えないで学習させます。
次のような教師なし学習の例が試験に出題されています。
正解のデータを提示せずに、統計的性質や、ある種の条件によって入力パターンを判定したり、クラスタリングしたりする。
(基本情報 平成31年春午前 問4より)
コンピュータ利用者の挙動データを蓄積し、挙動データの出現頻度に従って次の挙動を推論する。
(基本情報 平成31年春午前 問4より)
問題をチェック! 基礎 予想7
強化学習
Ver.5.0
強化学習は、正解を与えませんが、善し悪しの報酬・得点(スコア)を与えます。
次のような強化学習の例が試験に出題されています。
個々の行動に対しての善しあしを得点として与えることによって、得点が最も多く得られるような方策を学習する。
(基本情報 平成31年春午前 問4より)
回帰
シラ外
回帰は、教師あり学習の手法です。過去の連続するデータの傾向をもとに将来の値を予測する手法です。
分類
シラ外
分類は、教師あり学習の手法です。過去のデータの振り分け(分類)をもとに、未知のデータの分類を予測する手法です。
クラスタリング
シラ外
クラスタリングは、教師なし学習の手法です。データの特徴を分析し、類似度(お互いにどれだけ似ているか)にもとづいてデータをグループ分けしていく手法です。
ニューラルネットワーク
Ver.5.0
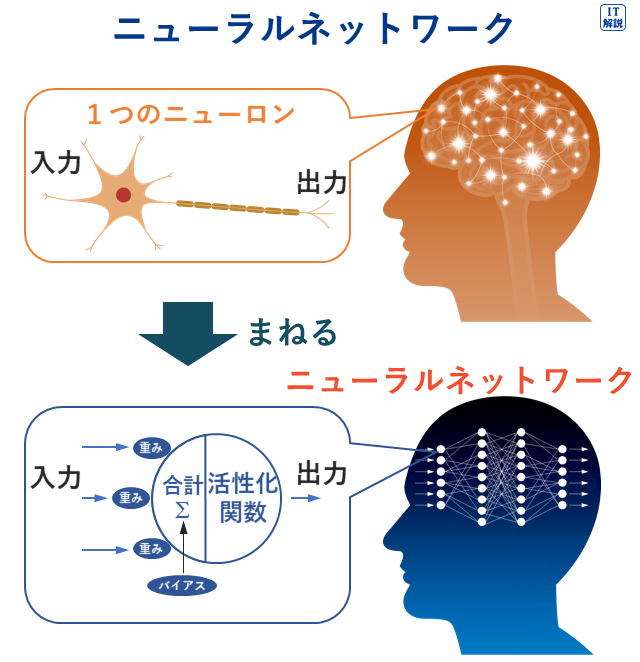
ニューラルネットワークは、人間の脳内にある神経回路を数学的なモデルで表現したものです。
(ITパスポート 令和2年 問19より)
次の用語と関連しています。
①ディープラーニング:
ニューラルネットワーク(大量のデータを人間の脳神経回路を模したモデル)で解析することによって、コンピュータ自体がデータの特徴を抽出、学習する技術
②データマイニング:
ニューラルネットワークや統計解析などの手法を使って、大量に蓄積されているデータから、特徴あるパターンを探し出す技術
問題をチェック!
R6年 問95 R5年 問74 R5年 問91
バックプロパゲーション
Ver.6.0
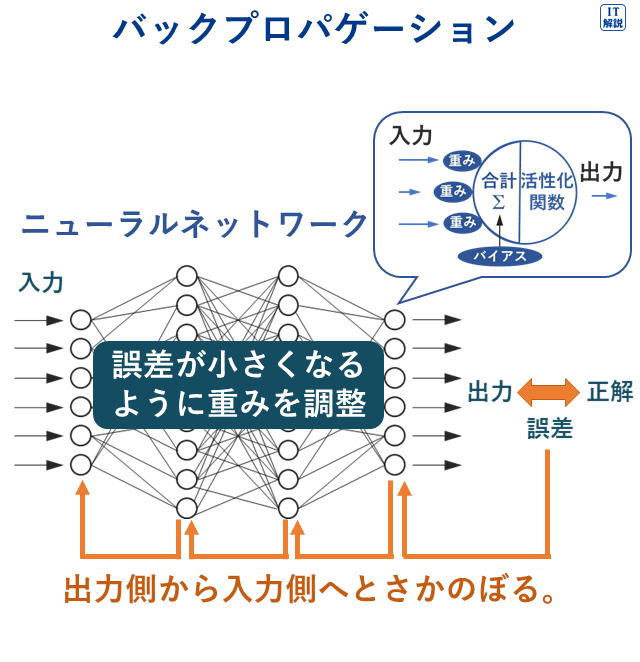
バックプロパゲーションは、ニューラルネットワークのトレーニング(調整)を効率よく行うアルゴリズムです。
ニューラルネットワークの出力と正解との誤差をもとに、出力側から入力側へとさかのぼって、ニューラルネットワークの重みとバイアスを最適化します。
活性化関数
Ver.5.0
活性化関数は、ニューラルネットワークの要素です。
問題をチェック! R5年 問91
過学習
Ver.6.2
過学習とは、機械学習を行う際にあらかじめ用意してある訓練データに過剰に適合しすぎ、未知データ(テストデータ)に対しては予測の性能が下がる(汎用性がなくなった)状態のことを指します。
問題をチェック! 基礎 予想12
ディープラーニング
Ver.5.0
ディープラーニングは、大量のデータをニューラルネットワークで解析して、データの特徴を抽出、学習する技術です。
(ITパスポート 令和元年 問21より)
問題をチェック!
R7年 問86 R4年 問67 R元年 問21
事前学習
Ver.6.2
事前学習とは、大規模なデータセットを用いて、ニューラルネットワークを初めて訓練することです。
事前学習のプロセスで、広範で一般的な知識を習得します。
この事前学習済みモデルを、ファインチューニング(微調整)することで、特定のタスク(作業)に適応させることができます。
ファインチューニング
Ver.6.2
ファインチューニングとは、機械学習で用いられる手法の1つです。
学習済みのモデルを利用して特定のタスク(用途)に対応したモデルを開発します。
学習済みのモデルに新たにモデルを追加し、学習済みの部分も含めて、特定タスクのためのデータセットを用いて再学習(モデルのパラメータを微調整)する手法です。
タスク(用途)ごとにデータをはじめから学ばせる必要がないので、効率良くモデルを作成できます。
問題をチェック! R7年 問80
転移学習
Ver.6.2
転移学習とは、機械学習で用いられる手法の1つです。
特定の領域で学習させたモデルを別の領域に適用する手法です。
学習済みのモデルに新たにモデルを追加し、学習済み部分のパラメータは変更せずに、別のデータセットを用いて再学習(モデルのパラメータを微調整)する手法です。
少ないデータで精度の高い学習結果を得ることが出来る可能性があります。
問題をチェック! 基礎 予想13
畳み込みニューラルネットワーク
Ver.6.2
畳み込みニューラルネットワーク(CNN、Convolutional Neural Network)
Convolutional(畳み込みの)
Neural(神経の)
Network(網状のもの)
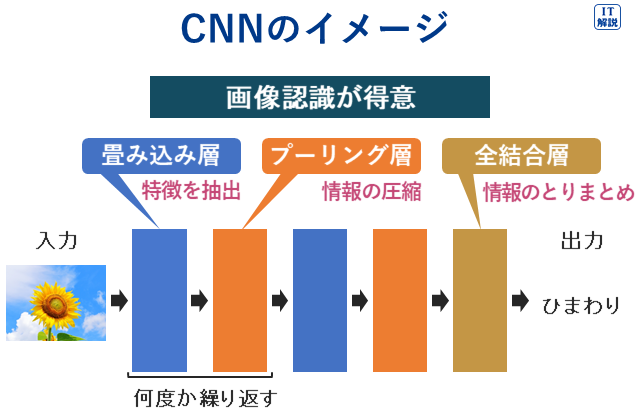
主に、画像認識や音声認識に活用されています。
CNNは、「畳み込み層」と「プーリング層」を有し、これらが働いて、データから特徴を抽出することが特徴です。
畳み込み層は、画像などの入力データに対して小さな窓(フィルターまたはカーネルとも呼ばれます)を移動させて、画像のどこを特徴として抽出するかを学習する層です。
プーリング層は、畳み込み層が抽出した特徴を残しつつ、データをより扱いやすいサイズにします。
再帰的ニューラルネットワーク
Ver.6.2
再帰的ニューラルネットワーク(RNN、Recurrent Neural Network)
Recurrent(再帰性の、戻ってくる性質の)
Neural(神経の)
Network(網状のもの)
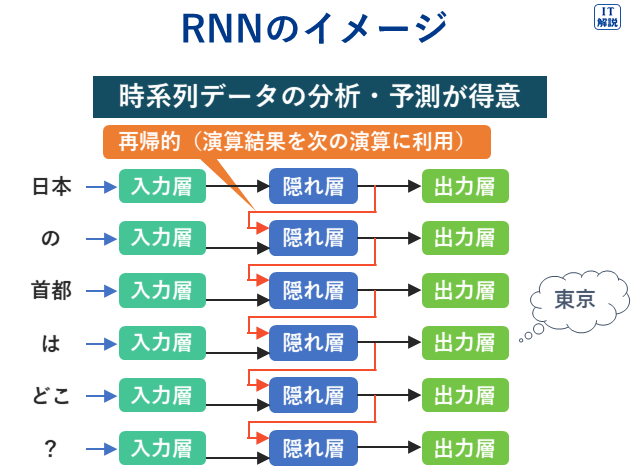
RNNは、過去の情報の入力から時系列データ(例えば動画や音声、株価など)の個々の要素の並びの依存関係を学習して出力することが特徴です。
人間の言葉の認識や生成、株価や売上などのような連続的なデータの分析と予測などに活用されています。
敵対的生成ネットワーク
Ver.6.2
敵対的生成ネットワーク(GAN、Generative Adversarial Networks)
Generative(生成的、生産または発生することのできる)
Adversarial(敵対的な)
Networks(網状のもの)
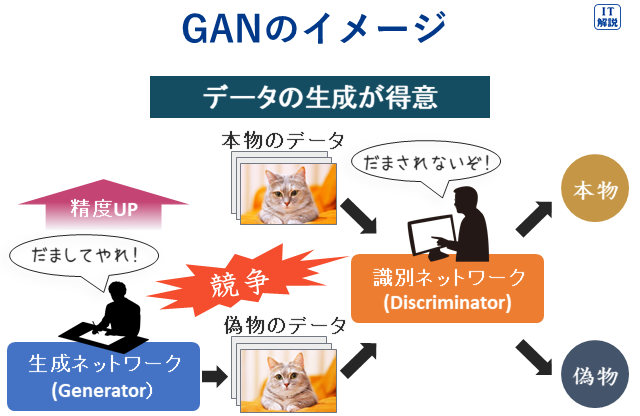
GANは生成モデルの1つです。
学習によって、学習したデータと似たような実在しないデータを生成することができ、画像生成などに活用されています。
GANは、Generator(生成ネットワーク)とDiscriminator(識別ネットワーク)の2つのネットワークから構成され、互いに競争させることで、生成データの精度を高めることが特徴です。
大規模言語モデル
Ver.6.2
LLM(Large Language Models:大規模言語モデル)
Large(大きい)
Language(言語)
Models(モデル)
大規模言語モデルは、自然言語処理の分野で使用される深層学習モデルの一つです。
ニューロネットワークに巨大なテキストデータを入力し、大量のパラメータを調整しながら膨大な計算を行って構築されています。
人間が普段使う言葉や言い回し、文法、意味を理解して、単語の次にどの単語が続くのかを予測することで、人間に近い流暢な会話を可能にしています。
プロンプトエンジニアリング
Ver.6.2
プロンプトエンジニアリングとは、生成AIから、より適切な回答が与えられるように、ユーザーの要求や意図を正確に理解させられるような指示文や質問文を設計する技術のことです。
再現率
シラ外
再現率は、機械学習などにおいて、あらかじめ人間が用意した正解データから、システムが正解と予測(判定)できたものの割合です。
問題をチェック! R5年 問76(計算問題)
エキスパートシステム
シラ外
エキスパートシステムは、特定の分野の専門知識をコンピュータに入力し、入力された知識を用いてコンピュータが推論する技術です。
(基本情報 平成30年秋午前 問3より)
「AならばBである」というルールを人聞があらかじめ設定して、新しい知識を論理式で表現したルールに基づく推論の結果として、解を求めます。
(基本情報 平成30年春午前 問3より)
次のようなエキスパートシステムの例が試験に出題されています。
健康診断結果や投薬情報など,類似した症例に基づく分析を行い,個人ごとに最適な健康アドバイスを提供できるシステム
(基本情報 平成26年秋午前 問63より)
まとめ
【学習ポイント】
・離散数学
→2進数の計算が時々出ています。対策しましょう。
・応用数学
→用語を覚えたら、本文にあるリンクを利用して、問題演習しましょう。
・情報に関する理論
→用語を覚えたら、本文にあるリンクを利用して、問題演習しましょう。
【重要用語】
新しい用語がたくさんあります。
基礎分野の問題は、用語を覚えただけでは解けない問題がよく出ます。
新しい用語の問題で、演習しましょう。




コメント