
最近の過去問題では、シラバス6以降の新出用語の出題が増えています。
しかし、公開されている新出用語の問題は、用語の数に比べてわずかしかありません。
シラバス6.2のときに増えた用語の意味を確認しましょう。
企業活動
精度と偏り(バイアス)
Ver.6.2
精度は、データのばらつきの程度を表す指標です。 観測データのばらつきが大きい場合、「精度が悪い」といいます。
偏りは、観測データから得た母集団の推定値と真の値との、傾向のある差異(偶然にできたものではないズレ)を指します。
統計的バイアス、選択バイアス、情報バイアス、認知バイアスなどがあります。
統計的バイアス
Ver.6.2
統計的バイアスは、標本抽出の方法や測定の方法によって、結果に生じる偏り(バイアス)です。選択バイアスや情報バイアスなどがあります。
選択バイアス
Ver.6.2
選択バイアスは、対象の選択で生じるバイアス(偏り)です。サンプリングした集団が母集団を代表しておらず、ある偏った特徴を有しているときに、結果にバイアス(偏り)が生じます。
情報バイアス
Ver.6.2
情報バイアスは、データの収集で生じるバイアス(偏り)です。観察や測定に誤りがあるときに、集められた情報によって、結果にバイアス(偏り)が生じます。
認知バイアス
Ver.6.2
認知バイアスとは、経験、先入観、固定概念、思い込みなどにより、合理的でない判断や選択をしてしまう心理現象のことです。
法務
エコーチェンバー
Ver.6.2
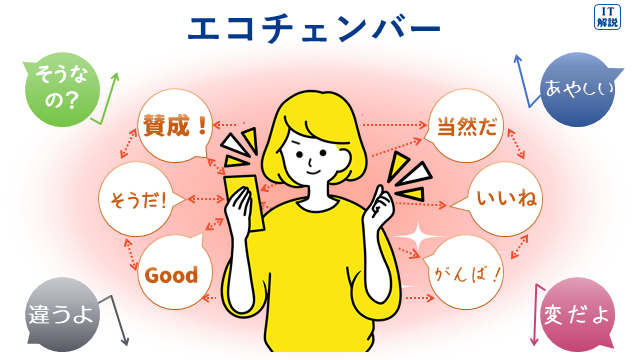
エコーチェンバーとは、SNSなどにおいて、同じような興味関心、価値観をもつユーザー同士でフォローしあった結果、自分が意見を発信した際に、同じような意見(自分に都合がいい意見)がばかりが返ってくる現象を指します。
不特定多数の人から、自分の意見に対して共感が得られることによって、誤った情報を正しいと思い込んでしまう危険があります。
フィルターバブル
Ver.6.2
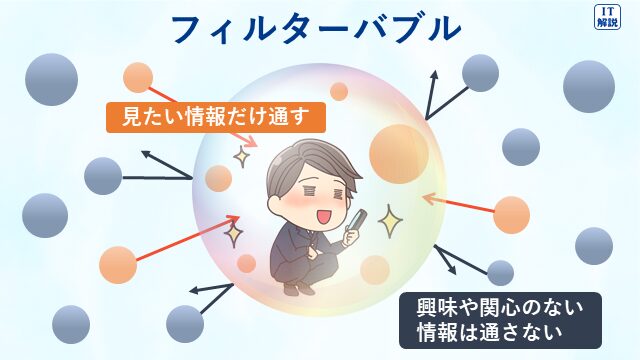
インターネットでは、検索エンジンのアルゴリズムが利用者個人の検索履歴やクリック履歴を分析・学習し、個々の利用者に合わせて、興味関心の高い情報が流れています。
フィルターバブルとは、バブル(泡)に閉じ込められたように、自分の興味関心に合わない情報からは隔離され、見たいものだけを見せられている状態を指します。
デジタルタトゥー
Ver.6.2

デジタルタトゥーとは、元のデータをインターネットから削除しても、コピーされたデータがSNSなどで瞬く間に拡散されると、インターネット上に半永久的に残ってしうことを指します。
一度インターネットで公開した情報を消すのが難しいことを、一度入れると消すことが難しいタトゥーになぞらえた用語です。
ビジネスインダストリ
生成AI
Ver.6.2
生成AIとは、AI(人工知能)を使って新しいデータを生成する技術のことです。生成AIは、入力されたデータを学習し、人間が作ったように自然な文章、音声、画像などを出力します。
マルチモーダルAI
Ver.6.2
マルチモーダルAIとは、複数種類のデータ(テキスト、音声、画像、動画、センサ情報など)を入力して、それらを統合的な処理をして結果を出力するAIです。
様々なデータを組み合わせることで、感情の推定など、より複雑な問題に適用できます。
ランダム性
Ver.6.2
ランダム性とは、生成AIにおける、既存のデータと異なるものを作る性質を指します。
ランダム性を調整することはできますが、同じプロンプトでも、全く同じデータを生成させることは困難です。
AIサービスが提供するAPIの活用
Ver.6.2
APIの利用により、開発期間・コストを掛けずに、AIを組み込んだサービス/アプリケーションを構築できます。
生成AIの活用
Ver.6.2
生成AIは、さまざまな領域で活用できます。
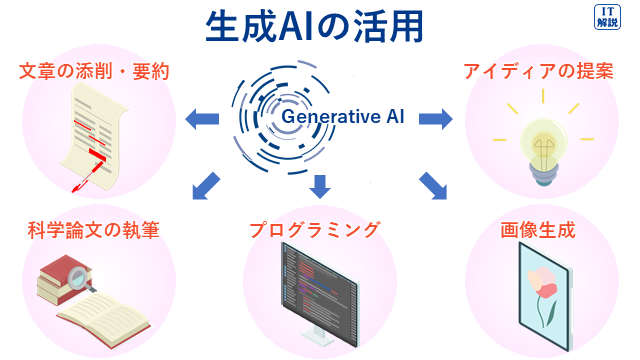
| 活用分野の例 | 内 容 |
| 文章の添削・要約 | 誤った文法構造、不適切な単語の使用、スペル(綴り)ミスなどを検出させる。 |
| アイディアの提案 | AIの回答を基にして、新しい視点や、情報の組み合わせのヒントを得る。 |
| 科学論文の執筆 | 質問に対して、世界中の論文を検索し重要なものを要約して紹介させる。 |
| プログラミング | 仕様を指示し、自動的にプログラムを生成させる。 |
| 画像生成 | 主に完成形のイメージや雰囲気をテキストで与え、画像を生成させる。 |
説明可能なAI(XAI)
Ver.6.2
| XAI(Explainable AI) | ||
| eXplainable(説明可能な) Artificial(人工的な) Intelligence(知能) |
説明可能な AIとは、予測や認識の判断をするまでの過程や根拠を説明できるAIを指します。
AIモデルは、構造が複雑で、人がその動作の全体を把握するのは困難であるため、AI導入の阻害要因となっています。そのためAIの動作を理解し、信頼して活用できるようにXAIの研究が行われています。
ヒューマンインザループ(HITL)
Ver.6.2
| HITL(Human-in-the-Loop) | ||
| Human-(人間) In-(中に) The- Loop(ループ、輪) |
ヒューマンインザループとは、AIにおける判断や制御のプロセスの一部に人間が介在し、システムと人間が協力して課題解決を目指す考え方です。
たとえば、業務知識が豊富な担当者が、AIモデルが導いた結果を確認し、間違っていると、結果を修正してモデルに改めて学習させ、より正確で効率的な結果が得られるようにします。
AI利用者の関与によるバイアス
Ver.6.2
バイアスは、「偏見」、「偏り」などを指します。
AIの判断は、学習時のデータに基づくため、利用者が提供する不正確な情報や偏った情報が反映される可能性があります。
たとえば、次のような例があります。
・不公平な判断が行われないようにアルゴリズムが設計されていても、データの代表性が確保されない(データが本来の母集団の特性を正確に反映していない)ことによってバイアスが生じる。
・国・地域などの集団ごとの社会通念の差異(例えば、ある集団では気にしないで扱われることが、別の集団では慎重に扱われること)により、社会的バイアスが入り込む。
(【別紙1(附属資料)】AI利活用原則の各論点に対する詳説 (soumu.go.jp)より)
ハルシネーション
Ver.6.2
ハルシネーションとは、AIが事実とは異なる情報を生成する現象のことです。
ディープフェイク
Ver.6.2
ディープフェイクとは、AIの技術を悪用し、実際の映像、音声、画像に偽の情報を組み込み、あたかも本物のように製作することや、そのようにして作られた映像、音声、画像を指します。
AIサービスのオプトアウトポリシー
Ver.6.2
AI サービスでは、利用者との対話情報や利用者のコンテンツ(文章や画像等)を保存し、AIサービスの開発や改善に使用することがあります。
これに対し、利用者は、オプトアウトポリシーを設定することで、利用者の対話情報やコンテンツの利用をAIサービス側に断ることができます。
基礎理論
自然言語処理
Ver.6.2
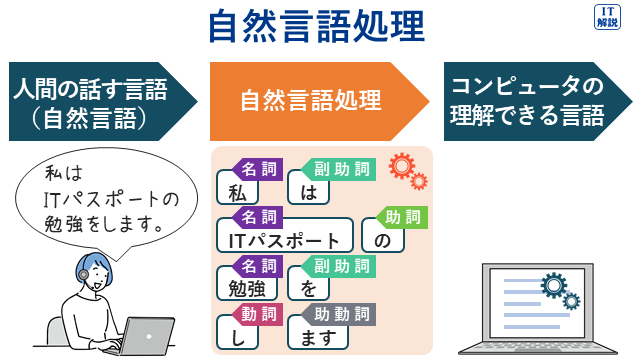
自然言語処理(NLP:Natural Language Processing)
「自然言語」とは、普段私たちが使っている言語のことで、「自然発生的に生まれた言語」のことを指します。プログラミング言語のような「人工言語」と対比する言葉です。
自然言語処理とは、人間の言葉をコンピュータの理解しやすい形に変換し、人間に近い解釈ができるように処理する技術です。
音声認識
Ver.6.2
音声認識とは、人の音声から、意味や、音色に関する情報(発声者、性別、喜怒の感情など)を識別する技術です。
音声からテキストを書き起こす議事録の自動化、スマート家電などに利用されています。
画像認識
Ver.6.2
画像認識とは、画像に写っているものの色や形といった特徴を読み取り、それが何であるかを識別して判断する技術です。
画像認識は、顔を特定するスマートフォンの顔認証システム、道路上の物体を検知する自動車の自動運転システム、製造ラインで不良品を発見する異常検知システムなどに利用されています。
過学習
Ver.6.2
過学習とは、機械学習を行う際にあらかじめ用意してある訓練データに過剰に適合しすぎ、未知データ(テストデータ)に対しては予測の性能が下がる(汎用性がなくなった)状態のことを指します。
基盤モデル
Ver.6.2
基盤モデルとは、大量で多様な「ラベルなしデータ」を使ってトレーニングを行い、その後、わずかな再トレーニングによって、用途に応じたカスタマイズができる汎用的なAIモデルです。
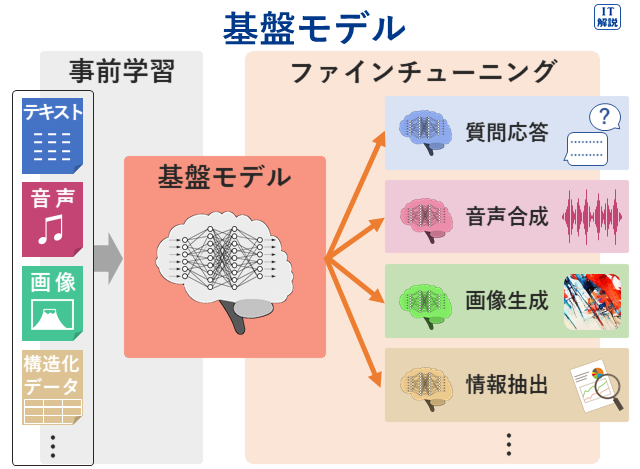
事前学習
Ver.6.2
事前学習とは、大規模なデータセットを用いて、ニューラルネットワークを初めて訓練することです。
事前学習のプロセスで、広範で一般的な知識を習得します。
この事前学習済みモデルを、ファインチューニング(微調整)することで、特定のタスク(作業)に適応させることができます。
ファインチューニング
Ver.6.2
ファインチューニングとは、機械学習で用いられる手法の1つです。
学習済みのモデルを利用して特定のタスク(用途)に対応したモデルを開発します。
学習済みのモデルに新たにモデルを追加し、学習済みの部分も含めて、特定タスクのためのデータセットを用いて再学習(モデルのパラメータを微調整)する手法です。
タスク(用途)ごとにデータをはじめから学ばせる必要がないので、効率良くモデルを作成できます。
転移学習
Ver.6.2
転移学習とは、機械学習で用いられる手法の1つです。
特定の領域で学習させたモデルを別の領域に適用する手法です。
学習済みのモデルに新たにモデルを追加し、学習済み部分のパラメータは変更せずに、別のデータセットを用いて再学習(モデルのパラメータを微調整)する手法です。
少ないデータで精度の高い学習結果を得ることが出来る可能性があります。
畳み込みニューラルネットワーク
Ver.6.2
畳み込みニューラルネットワーク(CNN、Convolutional Neural Network)
主に、画像認識や音声認識に活用されています。
CNNは、「畳み込み層」と「プーリング層」を有し、これらが働いて、データから特徴を抽出することが特徴です。
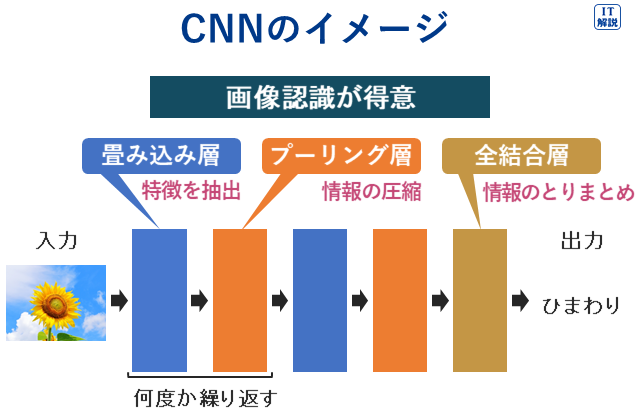
畳み込み層は、画像などの入力データに対して小さな窓(フィルターまたはカーネルとも呼ばれます)を移動させて、画像のどこを特徴として抽出するかを学習する層です。
プーリング層は、畳み込み層が抽出した特徴を残しつつ、データをより扱いやすいサイズにします。
再帰的ニューラルネットワーク
Ver.6.2
再帰的ニューラルネットワーク(RNN、Recurrent Neural Network)
RNNは、過去の情報の入力から時系列データ(例えば動画や音声、株価など)の個々の要素の並びの依存関係を学習して出力することが特徴です。
人間の言葉の認識や生成、株価や売上などのような連続的なデータの分析と予測などに活用されています。
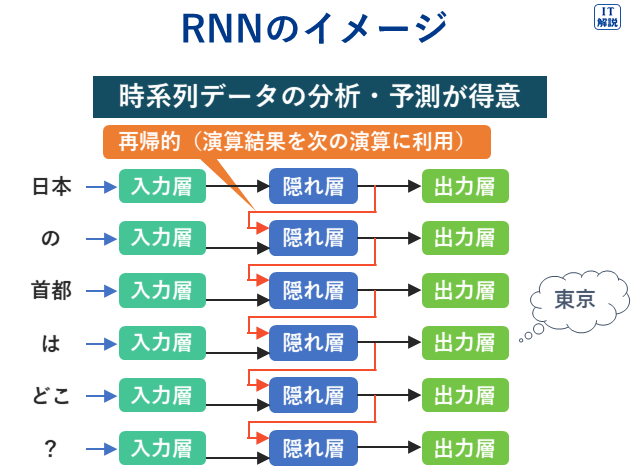
敵対的生成ネットワーク
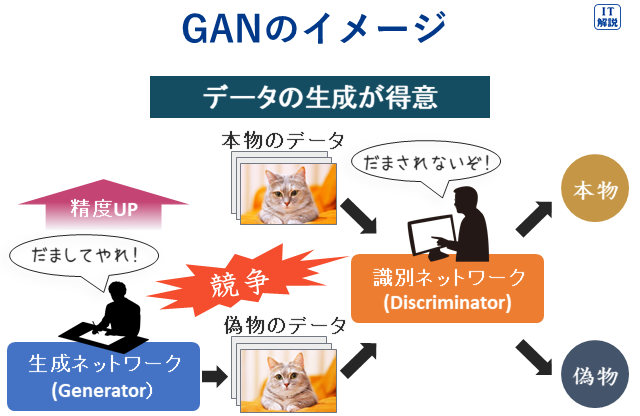
Ver.6.2
敵対的生成ネットワーク(GAN、Generative Adversarial Networks)
GANは生成モデルの1つです。
学習によって、学習したデータと似たような実在しないデータを生成することができ、画像生成などに活用されています。
GANは、Generator(生成ネットワーク)とDiscriminator(識別ネットワーク)の2つのネットワークから構成され、互いに競争させることで、生成データの精度を高めることが特徴です。
大規模言語モデル
Ver.6.2
大規模言語モデル(LLM、Large Language Models)
大規模言語モデルは、自然言語処理の分野で使用される深層学習モデルの一つです。
ニューロネットワークに巨大なテキストデータを入力し、大量のパラメータを調整しながら膨大な計算を行って構築されています。
人間が普段使う言葉や言い回し、文法、意味を理解して、単語の次にどの単語が続くのかを予測することで、人間に近い流暢な会話を可能にしています。
プロンプトエンジニアリング
Ver.6.2
プロンプトエンジニアリングとは、生成AIから、より適切な回答が与えられるように、ユーザーの要求や意図を正確に理解させられるような指示文や質問文を設計する技術のことです。
セキュリティ
プロンプトインジェクション攻撃
Ver.6.2
プロンプトインジェクションとは、意図的に不正なプロンプト(指示や質問)を注入(インジェクション)して、AIモデルにサービス側の意図しない内容を出力させたり、不適切な情報(例えば、プロンプト自体)を開示させる攻撃のことです。
敵対的サンプル
Ver.6.2
敵対的サンプル(Adversarial Examples)
敵対的サンプルとは、AIが誤って分類するように、人間にはわからないようなわずかなノイズを入れたデータを指します。
まとめ
最近の過去問題では、シラバス6以降の新出用語の出題が増えています。
そこで、シラバス6.2のときに増えた用語をまとめて解説しました。
なお、次の用語集にも、新出用語をまとめてあります。ご利用ください。


また、試験では「新しい用語と他の用語の意味の違い」などが問われます。
よく出る用語集で違いを確認しておくことをお勧めします。




コメント