
生成AIについてのサンプル問題(「ITパスポート試験 生成AIに関するサンプル問題」(PDF:85 KB))を解説します。
問1
生成AIの特徴を踏まえて、システム開発に生成AIを活用する事例はどれか。
出典:ITパスポート試験 生成AIに関するサンプル問題
正解の理由
生成AIとは、AI(人工知能)を使って新しいデータを生成する技術のことです。
生成AIは、入力されたデータを学習し、人間が作ったように自然な文章、音声、画像もできます。また、プログラムコードを生成することもできます。
自然言語は、私たちが使っている言葉のことです。
システム要件は、新たに構築する業務、システムの仕様、及びシステム化の範囲と機能などを指します。
E-R図は、対象世界を構成する実体(人、物、場所、事象など)と実体間の関連を表した図です。
(ITパスポート 平成24年秋 問53より)
選択肢に説明を加えて考えます。
(元の文章)
ウ 対象業務や出力形式などを自然言語で指示し、その指示に基づいて E-R 図やシステムの処理フローなどの図を描画するコードを生成AIに出力させる。
(説明を加えた文章)
ウ 対象の業務や出力の形式などを人間が普段使っている言葉で指示し、その指示に従ってE-R図(人、物、場所、事象などの関連を表す図)やシステムが処理する手順を示す図を描くための、コンピュータの命令やデータを生成AIに出力させる。
人間の言葉から対象の関係や手順を創造して図に示すので、生成AIを活用する事例です。
よって、正解は ウ です。
不正解の理由
それぞれの選択肢に説明を加えて考えます。
(元の文章)
ア 開発環境から別の環境へのプログラムのリリースや定義済みのテストプログラムの実行、テスト結果の出力などの一連の処理を生成AI に自動実行させる。
(説明を加えた文章)
ア 開発の作業環境(コンピュータやパソコンなど)から別の環境へプログラムを提供することや、あらかじめ用意してあるテストプログラムの実行、テスト結果の出力など一連の処理を生成AIに自動で実行させる。
あらかじめ決められてた処理の自動化で、新しいデータを生成していません。生成AIを活用する事例として不適切です。
(元の文章)
イ システム要件を与えずに、GUI上の設定や簡易な数式を示すことによって、システム全体を生成 AI に開発させる。
(説明を加えた文章)
イ システムの仕様、システム化の範囲と機能など要件を与えずに、操作画面のメニューやアイコン、ボタンの数、形、色などの設定や簡単な数式を示すことで、システム全体を生成AIに開発させる。
要件を与えられないので、生成AIを活用する事例として不適切です。
(元の文章)
エ プログラムが動作するのに必要な性能条件をクラウドサービス上で選択して、プログラムが動作する複数台のサーバを生成AIに構築させる。
(説明を加えた文章)
エ プログラムが動作するのに必要な性能条件(OS、開発言語、メモリ、ディスク容量など)をインターネット経由で提供されるサービスから選択して、プログラムが動作するサーバを構成する複数台のコンピュータへの設定を生成AIにさせる。
選択された性能条件に従って自動的に作業させるだけで、新しいデータを生成していません。生成AIを活用する事例として不適切です。
問2
生成AIが、学習データの誤りや不足などによって、事実とは異なる情報や無関係な情報を、もっともらしい情報として生成する事象を指す用語として、最も適切なものはどれか。
出典:ITパスポート試験 生成AIに関するサンプル問題
正解の理由
ハルシネーションとは、AIが事実とは異なる情報を生成する現象のことです。
問題に「事実とは異なる情報や無関係な情報を、もっともらしい情報として生成する事象」とあるので、ハルシネーションが適切です。
よって、正解は エ です。
不正解の理由
ア アノテーションとは、テキストや音声、画像といったさまざまなデータに、情報タグ(メタデータ)を付ける(注釈を付ける)ことを指します。機械学習のモデルに学習させる教師データを作成する際に行います。
イ ディープフェイクとは、AIの技術を悪用し、実際の映像、音声、画像に偽の情報を組み込み、あたかも本物のように製作することや、そのようにして作られた映像・音声、画像を指します。
ウ バイアスには、「偏り」「偏見」「先入観」などの意味があります。 偏った学習データを与えることで、AIの出力する結果に反映されることがあります。
問3
AIにおける基盤モデルの特徴として、最も適切なものはどれか。
出典:ITパスポート試験 生成AIに関するサンプル問題
正解の理由
基盤モデルとは、大量で多様な「ラベルなしデータ」を使ってトレーニングを行い、その後、わずかな再トレーニングによって、用途に応じたカスタマイズができる汎用的なAIモデルです。
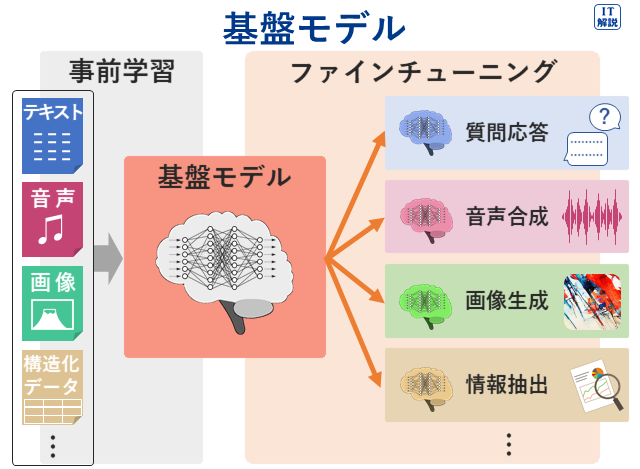
「広範囲かつ大量のラベルなしデータを用意して事前学習しておき、その後の学習を通じて微調整を行うことによって、質問応答や画像識別など、幅広い用途に適応できる」とあるので、AIにおける基盤モデルの特徴です。
よって、正解は ウ です。
不正解の理由
ア 「“A ならば B である”といったルールを大量に学習しておき、それらのルールに基づいた演繹(えんえき)的な判断の結果を応答する。」は、ルールベースAIの記述です。
イ 「機械学習用の画像データに」「情報を注釈として付与した学習データを作成し」とあり、ラベルなしデータでないので基板モデルの記述でありません。
エ 「想定値より大きく外れている例外データだけを学習させる」は、偏ったデータを学習させることなので不適切です。
ここまで、IPAが公開した生成AIの問題と解説を紹介しました。


コメント